计算机科学、密码学创始者艾伦·麦席森·图灵在1950年撰写《计算机器与智能》一文,提出一项经典测试:倘若一台机器与人类展开对话,超过30%测试人类误以为在、人类说话而非机器,那么就可以说这台机器具有智能,
这就是人工智能行业著名“图灵测试”,图灵预言在20世纪末一定会有电脑经由这项测试,但事实上直到2014年,人工智能软件“尤金·古斯特曼”才最先個個经由图灵测试,这也从侧面体现出一個事实:虽说早在70多年前就已经有科学家实行猜想,但让赋予机器人“灵魂”,却依旧任重道远,那么难题来,目前人工智能处于相对高速发展阶段,咱们有哪些能让让机器人与咱们交互呢?

让机器人“看见”世界
作为地球上最有智慧生物,人类获取信息渠道83%来自视觉,11%来自听觉、3.5%来自嗅觉,而1.5%来自触觉,1%来自味觉,而既然要模拟人类思维方法,其重心就是让机器经由深度学习,根据所收集数据信息做出相应反馈,探究到咱们大一部分信息来源都是视觉,所以,让机器人“看到”物体、场景,进而对图像内容给予解释就成机器人灵魂重心,
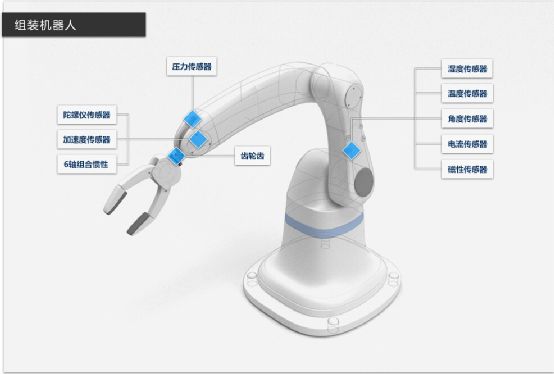
工厂里最常见机器人也同样有着丰富感知传感器
目前伴随对人工智能视觉技术连续进化,涵盖物体识别、意向追踪、领航、避障已变成各类智能设备前端通用技术,咱们在工业生产自动化、流水线控制、汽车自动驾驶、安防监控、遥感图像分析、无人机、农业生产以及机器人等各個方面都能找到很多案例,比方说上海人工智能研究院研发核酸采样机器人:经由视觉传感器识他人脸位置,以及嘴部张开动作是否符合采样要求,机械臂将棉签伸入后利用内窥视觉系统检测口腔内环境,识别扁桃体并引导棉签采集扁桃体附近分泌物,力控传感器则能实时反馈力控数据,将机械臂力量控制在保障阈值内,22秒左右就能完成一次无人核酸采样,这就是典型依靠环境感知自动化机器人,

结合视觉与触觉传感器,核酸采样机器人可以完成无人化采样任务
而对于移动机器人来说,就须要运用多种不同样传感器来实行环境感知,比方说大家在饭点餐馆大概会看到自动传菜机器人,亦或是在工厂里很常见运输机器人,它们会经由搭载激光雷达、立体视觉摄像头、红外以及超宽频传感器来“分辨”环境并构建地图,于是持有识别、感知、理解、判断及行动本事,
环境感知本事是机器人最基本功能,这意味着这类机器人更适用于服务型就业,目前来看这类机器人还可以经由模块化装备,完成人员异常行为监测、人员检测及记录、异常高温或火灾报警、环境数据异常报警等功能,甚至经由远程监控模块,可以代替人员进入危险场所,完成勘察任务,
让机器人“开口说话”
倘若只是经由环境感知来完成就业,这样机器人算得上“聪明”么?站在人类角度来看但是也都是自动化工具而已,离咱们想象中电影里那样智能化机器人有着非常明显差距,其实很大层次上引发这种感觉原因在于,服务型机器人大多都不会与人实行交互,而咱们人类交互重心方法就是说话聊天,70多年前提出图灵测试还是经由文字格局来验证,而现在倘若要重新定义话,语音交互应该是必考项目,比尔·盖茨就曾说“人类自然形成与自然界沟通认知习惯、格局必然是人机交互发展方向”,
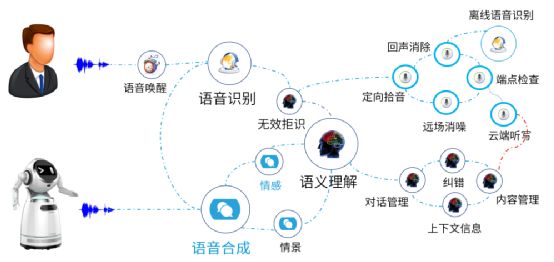
看似简单对话,却蕴含多個解析步骤
人机交互技术最先选包含语音识别、语义理解、人脸识别、图像识别、体感/手势交互等技术,其中语音人机交互过程中包含信息输入、输出、语音搞定、语义分析、智能逻辑搞定以及知识、内容整合,
就目前来看,人工智能语音技术可以分为近场语音、远场语音两個分类,近场语音基本上是为满足一些辅助运用需求,比方说苹果Siri、微软小冰就是近场语音产品吗,而很多智能音箱则可以实行远场语音,运用者能在5米外距离语音指示它控制智能家居设备,这些看起来似乎很简单就业,事实上对准确性要求非常高,从搞定过程来看先要经由声学搞定咱们声音、周围环境,再经由语音识别技术将听到声音翻译成文字,语义理解技术则会分析这些文字意义,最后机器去执行运用者指令或者经由语音合成技术把要表达内容合成语音,
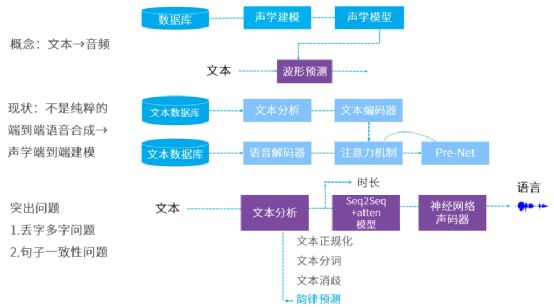
机器人语义理解本事目前仍属于较低水平
但在真实环境下,受噪音等环境因素影响,机器依旧无法百分之百准确识别自然语言,机器将听到语音翻译成文字时,重音、口音模糊、语法模糊等又很影响成功率,况且人类语言太复杂,受到单词边界模糊、多义词、句法模糊、上下文理解等影响,再加上中文存在大量方言,语义理解是一個巨大障碍,
所以,现阶段人工智能语音系统更多用在垂直运用场景,比方说汽车车载智能语音系统、儿童娱乐、教育软件、人工智能客服等等,尤其是人工智能客服,很多人应该都接到过银行或金融机构智能客服电话,大多数情况下它表现都跟真人没有太大差别,但严重缺乏变通本事,只能在相对狭窄范围内实行沟通,准确率也并非高,但它一则可以实行客户需求高速响应,二来在一定层次上能够节约时间、人工本钱,所以在后世也一定会伴随渗透率连续加深而继续进化,
让机器人更“聪明”
既然咱们说到机器人智能进化,大概有读者朋友会问:那它是怎样进化呢?最著名方法就是深度学习,早在2011年,谷歌一家实验室研究人员从影像网站中抽奖1000万张静态图片,把它“喂”给谷歌大脑,意向是从中探寻重复发生图片,而在足足3天后,谷歌大脑才完成这一挑战,而谷歌大脑就是一個由1000台电脑、16000颗搞定器组成10亿神经单元深度学习模型,
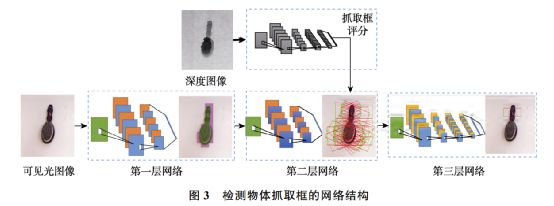
机器人抓取姿态判别深度学习方案
深度学习概念源于人工神经网络研究,本质上是构建含有多隐层机器学习架构模型,经由大规模数据实行训练,得到大量更具典型特征信息,于是对样本实行分类、占卜,提高分类、占卜精度,比方说抓取姿态判别,对于人类来说,想要拿起一個东西只须要看几眼就晓得该用怎样手势去拿,而对机器人来说这却是一個不小挑战,涉及到研究涵盖智能学习、抓取位姿判别、机器人运动规划与控制;况且还须要根据抓取物体材质性质来随机应变,调整抓取姿势、力度,
但是,创造一個无敌神经网络需更多搞定层,这就须要很强数据搞定本事,所以深度学习背后往往都有上游硬件大佬“撑腰”,这些年图形搞定器、超级计算机、云计算迅猛发展,让深度学习脱颖而出,NVIDIA、英特尔、AMD等芯片巨头都站到人工智能学习舞台中央,
深度学习技术奠定在大量实例基石上,给它学习数据越多,它就越聪明,因大数据无法或缺,所以目前深度学习做得最非常好基本是持有大量数据IT巨头,如谷歌、微软、百度等,
与此同时深度学习技术在语音识别、计算机视觉、语言翻译等领域,均战胜传统机器学习方法,甚至在人脸验证、图像分类上还超过人类识别本事,比方说短影像阶段很热门人工智能“换脸”,就是将原影像里人脸逐帧导出,再经由大量想要替换人脸照片来实行模型训练,训练过程你会直观看到替换人脸从模糊逐渐变得清晰,根据电脑配置不同样,在训练数小时甚至数十小时后就能得到一個相当没错替换结果,这就是深度学习典型过程,
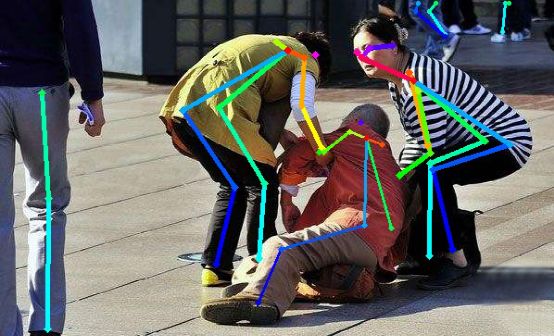
姿态识别也是机器人视觉学习根本点之一
对于机器人来说,深度学习应用面除图像识别之外也还有很多,比方说工业或安防机器人须要用到复杂环境路线规划、室内领航,教育机器人识别学生坐姿、举手、摔倒人体姿态判断等,在后世,计算方法大概更趋向于与大数据、云计算相结合,使机器人利用云平台更好地存储资源、自主学习,同时在大数据环境下,数量浩大机器人一道共享学习内容,叠加学习模型,更有效地分析、搞定海量数据,于是提高学习、就业效能,发展智能机器人潜力,
显然,这些发展也还存在很多隐藏难题,比方说在机器人与云平台相结合时,因技术还不够成熟,在资源分配、系统保障、权威有效通信协议,以及如何打通各大上游厂商之间技术壁垒等都是下一步研究中须要Follow难题。
编辑|张毅
审核|吴新